Настройка алертов¶
Retroview предоставляет мощные инструменты для мониторинга серверов и диагностики входящих потоков. Однако мониторинг становится по-настоящему эффективным, когда вы получаете уведомления о проблемах до того, как они повлияют на пользователей.
Дашборд Alerts dashboard позволяет настроить алерты для всех критических метрик и событий, которые описаны в документации по мониторингу серверов и захвата. Ниже — пошаговое руководство по работе с дашбордом, а далее — описание каждого типа алерта и рекомендации по реагированию.
Дашборд Alerts dashboard¶
На дашборд можно попасть двумя способами:
- из личного кабинета — во вкладке Статистика нажмите кнопку Создание алертов;
- в Grafana — через вкладку Dashboards, затем откройте дашборд Alerts dashboard.
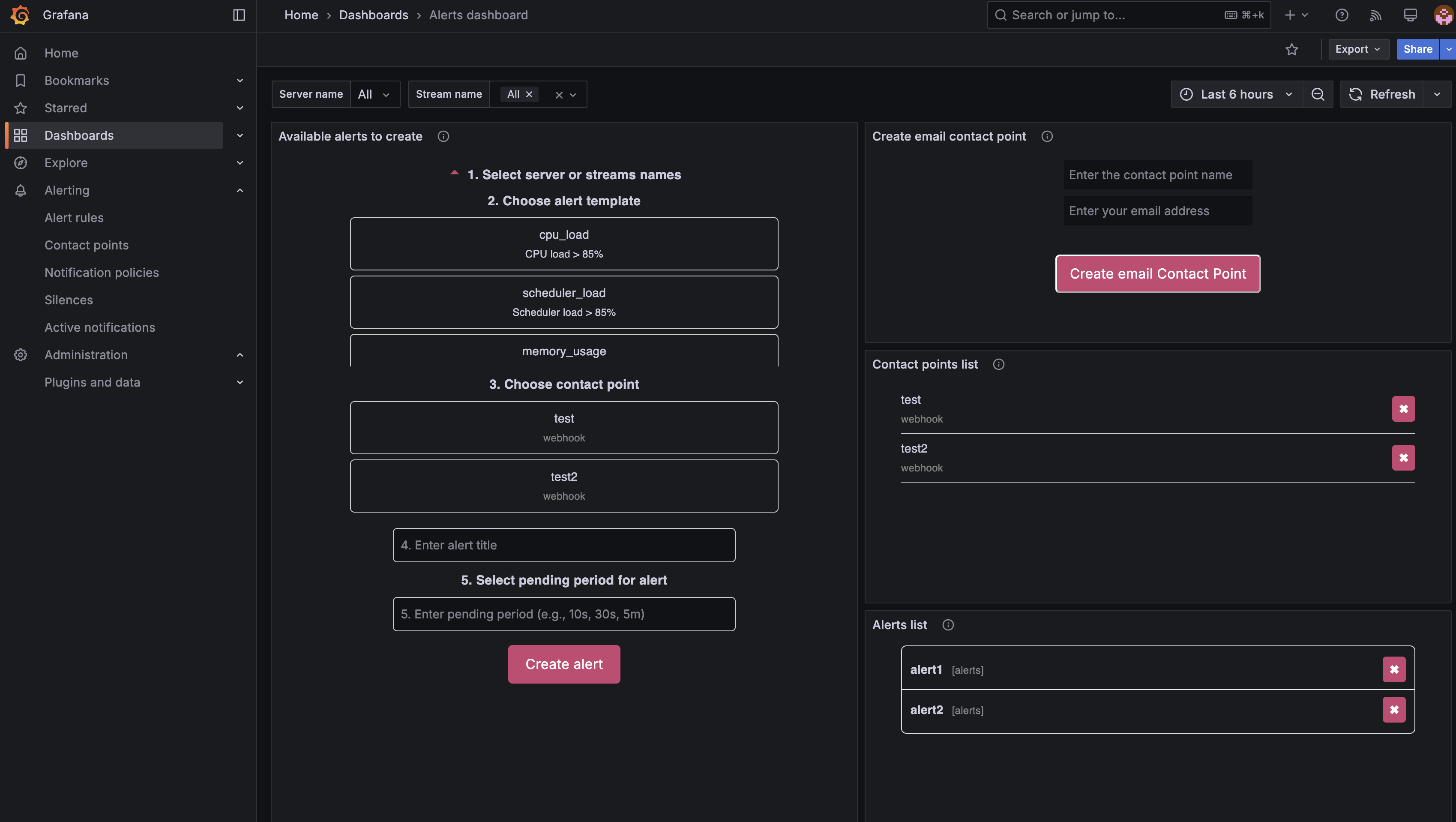
На дашборде собраны все инструменты для создания алертов и управления ими: форма создания, списки контактных точек и активных алертов. Далее описан полный цикл — от настройки уведомлений до создания правил.
Создание алерта¶
Создание алерта на дашборде состоит из шести шагов:
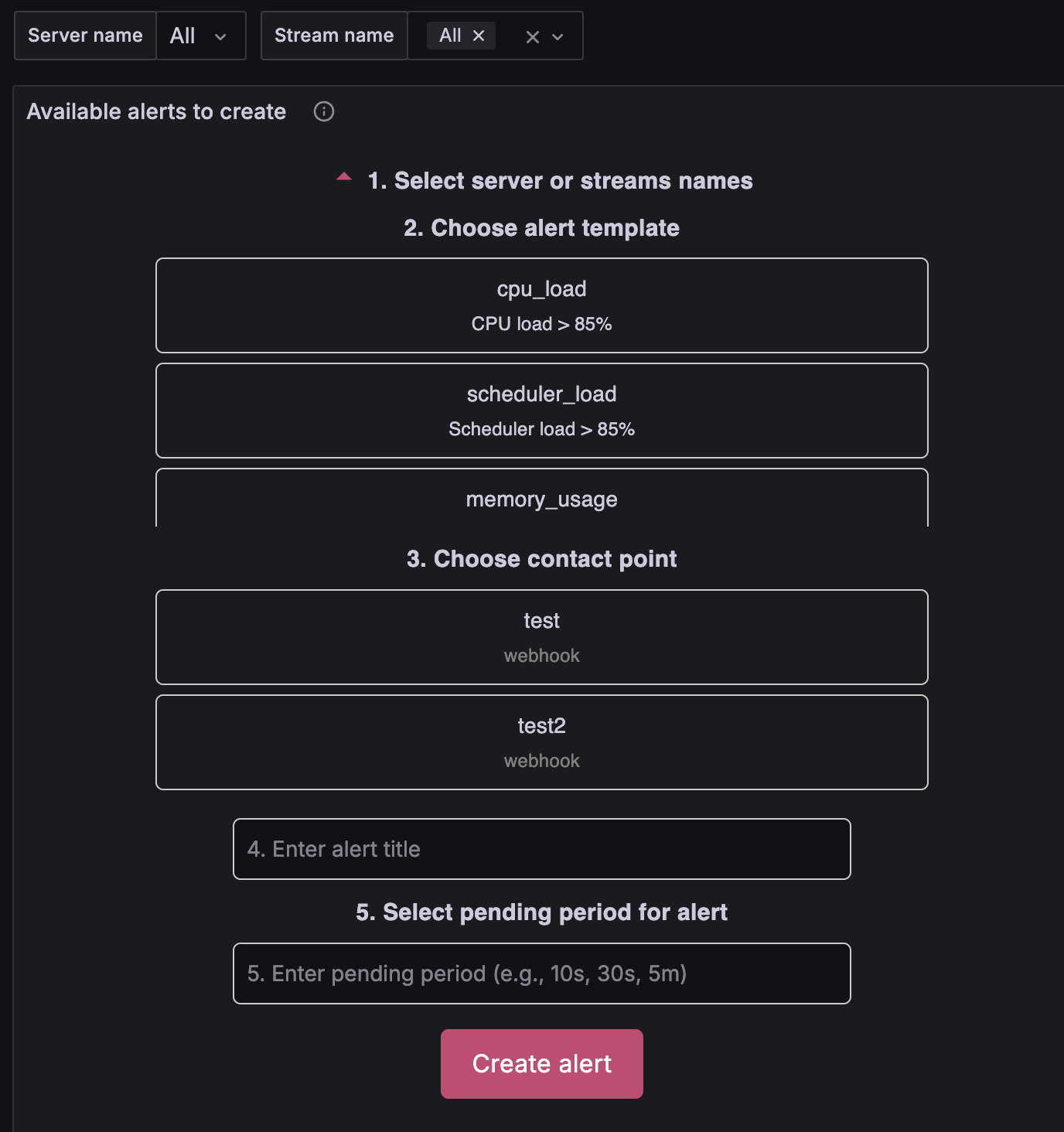
1. Выбор сервера или потока — укажите, к какому серверу (или потоку) будет применяться алерт. Для части алертов доступна опция All, чтобы правило действовало на все серверы сразу.
2. Выбор типа алерта — в блоке Available alerts to create выберите нужный алерт. Описание каждого типа — в разделах Проблемы серверов и Проблемы входящих потоков ниже.
3. Выбор контактной точки — укажите, куда отправлять уведомление. Для email создайте точку прямо на дашборде — см. Создание email контактной точки. Для Telegram, Slack и других каналов — Контактные точки для других каналов.
4. Название алерта — имя, под которым правило будет отображаться в списке. Выбирайте понятное название, например: «Production Server CPU Critical» или «VIP Channels Down Alert».
5. Время ожидания (pending period) — интервал, в течение которого условие алерта должно оставаться истинным, прежде чем сработает уведомление. Если условие исчезнет раньше — алерт не сработает.
Допустимые форматы:
10s(10 секунд) — для критичных алертов по VIP-потокам30s(30 секунд) — для важных алертов1m(1 минута — рекомендуется по умолчанию)5m(5 минут) — для некритичных предупреждений1h(1 час) — для мониторинга трендов
Рекомендация: для алертов по серверам (CPU, memory, disk) используйте 1m или 5m, чтобы избежать ложных срабатываний на кратковременных всплесках. Для критичных потоков можно использовать 30s или 10s.
6. Создание — если все поля заполнены, нажмите кнопку создания алерта. Правило появится в списке созданных алертов.
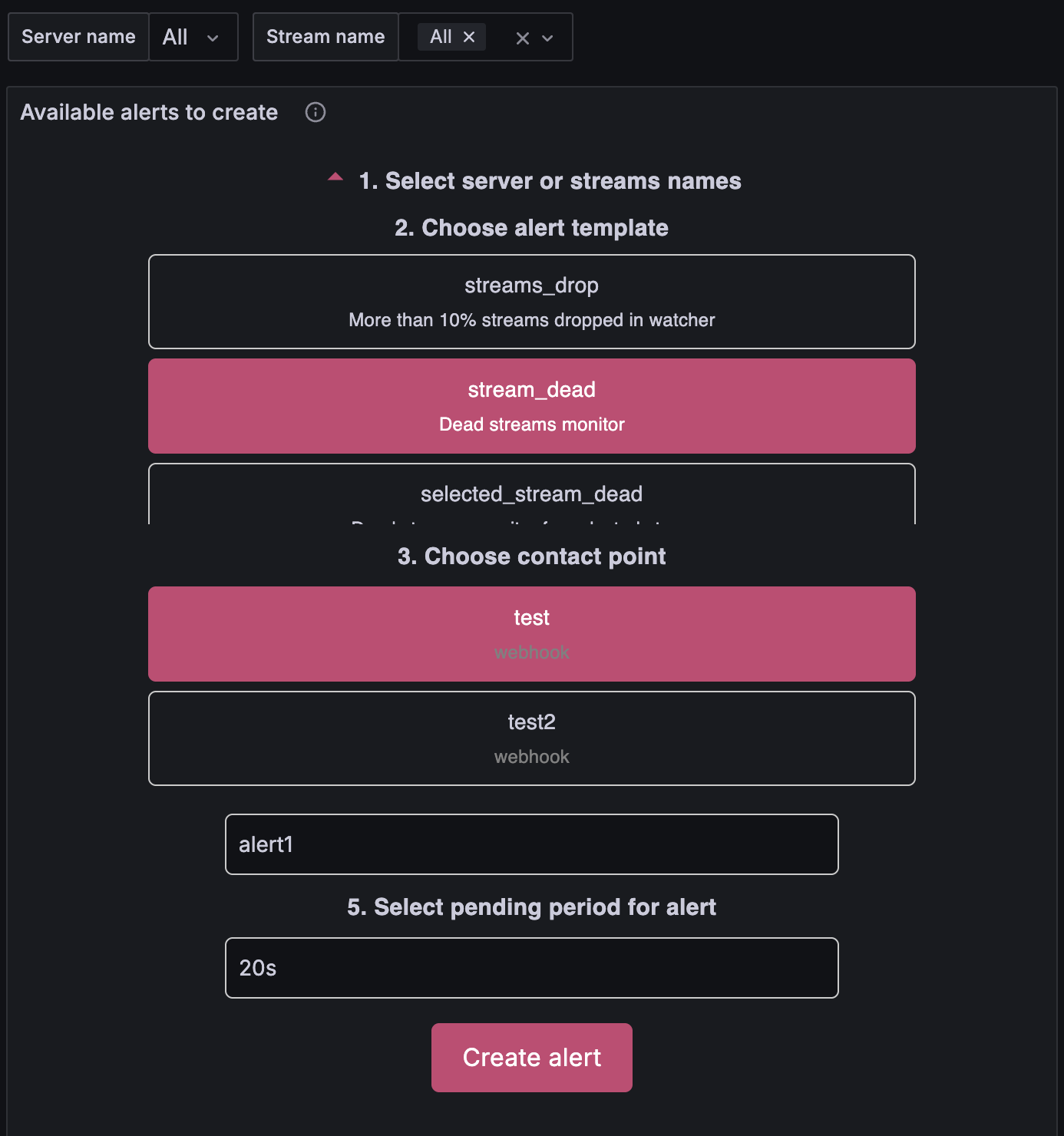
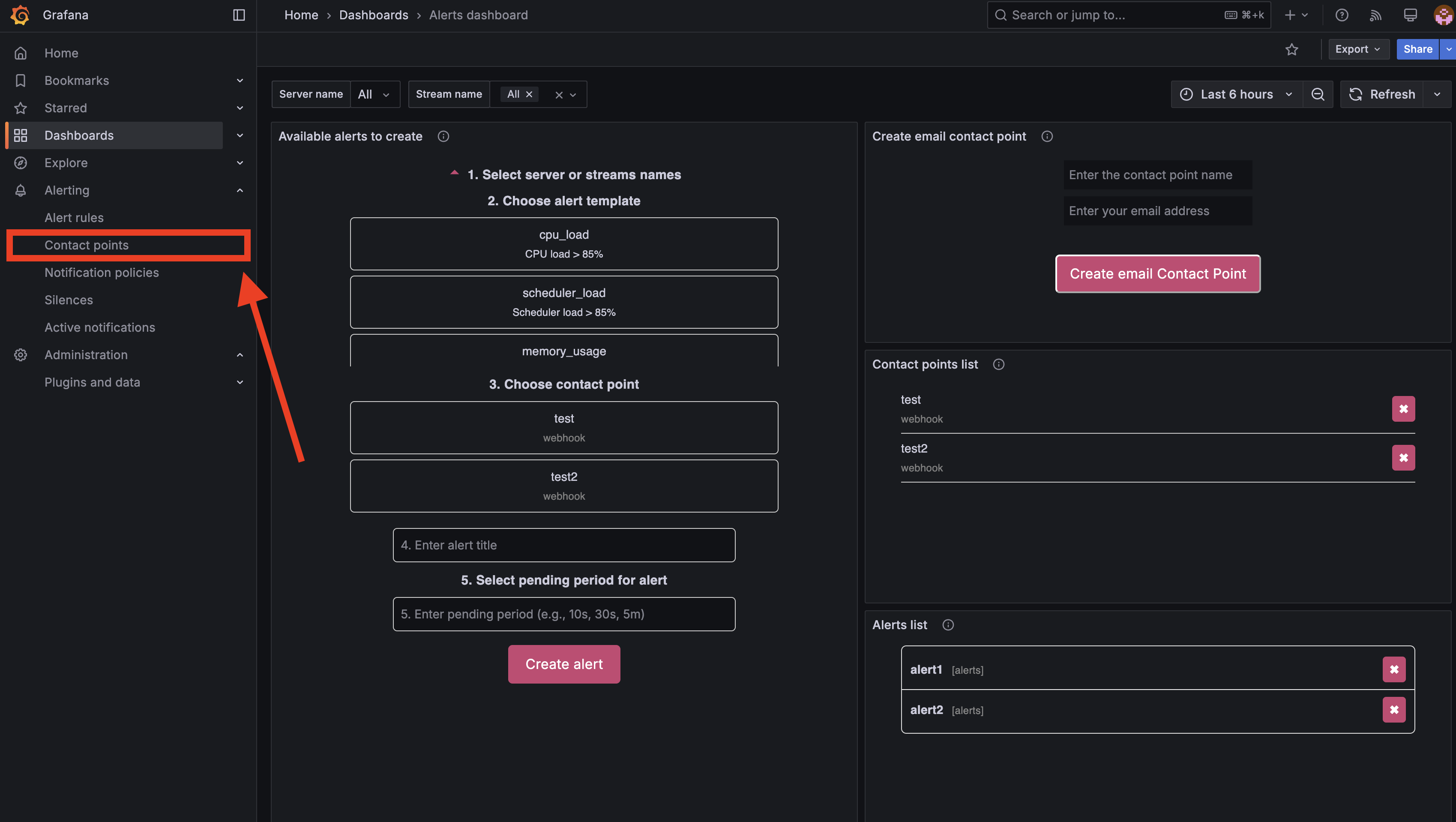
Пример создания алерта¶
На скриншоте ниже — готовый пример:
- сервер: All (все серверы);
- тип алерта: stream_dead;
- контактная точка: test;
- название: alert1;
- время срабатывания: 20 секунд.
Создание email контактной точки¶
Для отправки алертов на почту контактную точку нужно создать только через форму на дашборде — раздел Create email contact point.
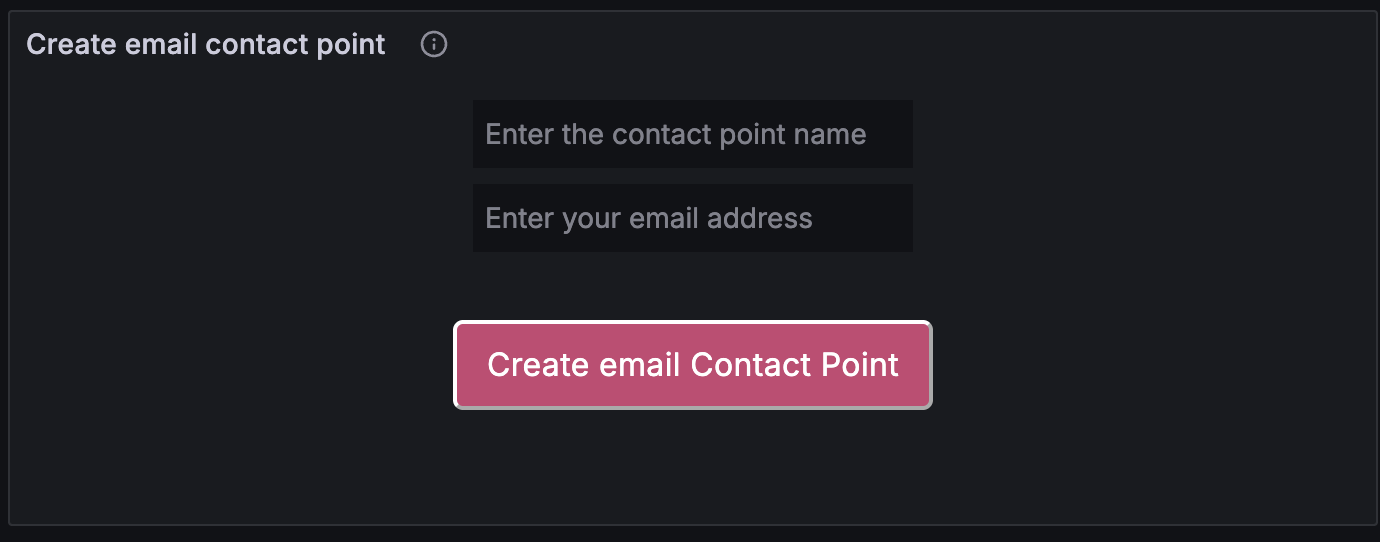
1. Имя контакта — введите уникальное имя. Оно появится в выпадающем списке при создании алерта.
2. Email адреса — один или несколько адресов для получения уведомлений. Несколько адресов разделяйте запятыми:
example@mymail.com,example2@mymail.com
После сохранения контактная точка появится в списке контактных точек и станет доступна при создании алертов.
Список контактных точек¶
Блок показывает все созданные контактные точки — email и другие типы, которые уже настроены для дашборда.
Отображаемая информация:
- Тип — Email, Webhook, Telegram и т.д.
- Имя — уникальное имя, заданное при создании
Управление: у каждой точки есть кнопка ✕ — нажатие удалит контакт.
Для просмотра или расширенной настройки в Grafana перейдите в:
Grafana → Alerting → Contact points
Список созданных алертов¶
Блок отображает все активные правила, созданные через дашборд.
Отображаемая информация:
- Имя алерта — название, заданное при создании
- Папка — папка или группа, к которой принадлежит правило
- Статус — если алерт приостановлен, появится метка
paused
Управление: у каждого алерта есть кнопка ✕ — нажатие удалит правило.
Для полной информации и логики срабатывания перейдите в:
Grafana → Alerting → Alert rules
Контактные точки для других каналов¶
Если уведомления нужны не на email, а в Telegram, Slack, webhook и т.д., контактную точку создают в Grafana.
Важно: для отправки алертов на почту используйте только форму на дашборде. Через Grafana email-точки для этого дашборда не настраиваются.
1. В Grafana откройте Alerting → Contact points:
2. Нажмите Create contact point:
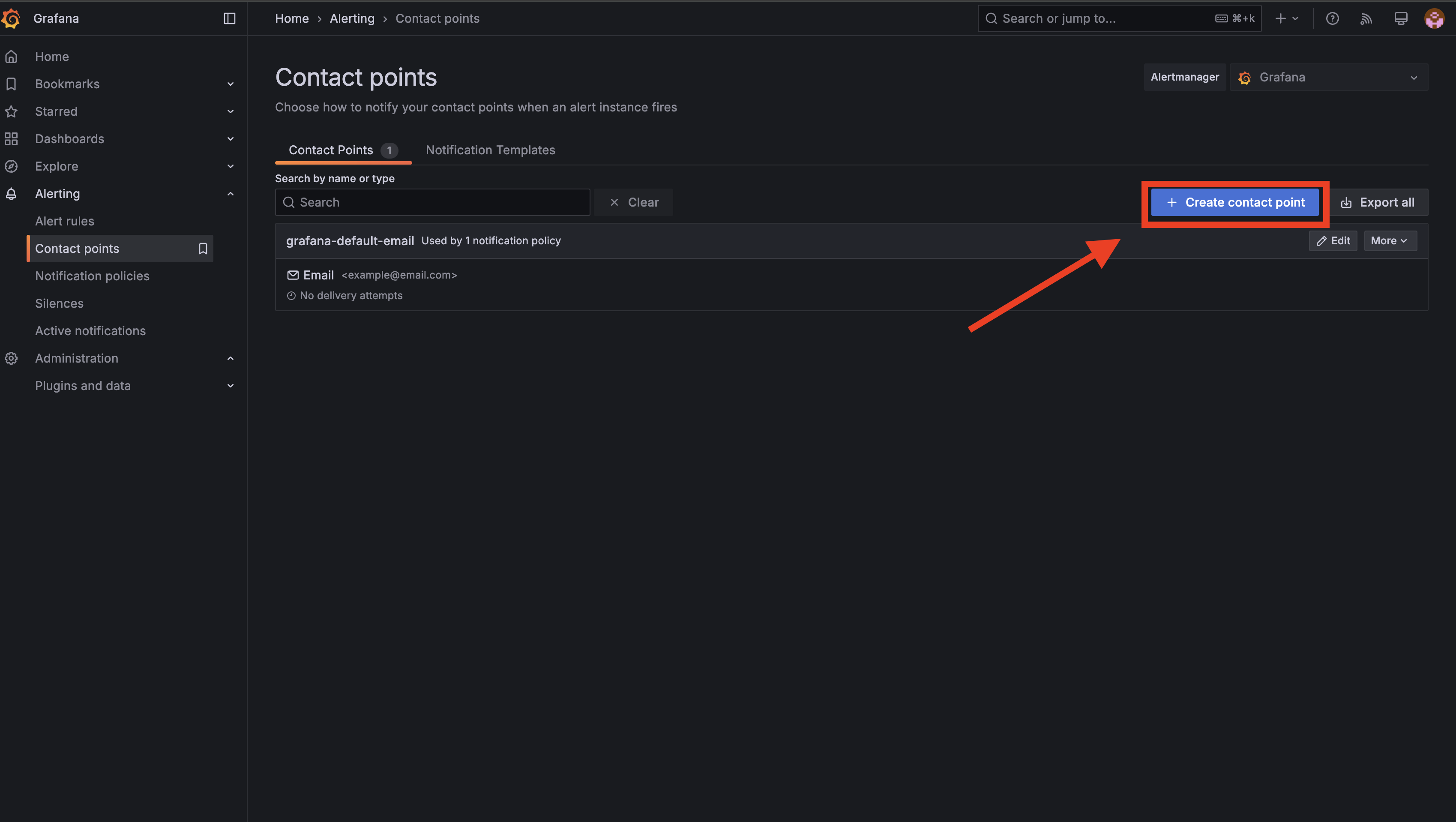
3. Выберите тип канала (не Email), заполните обязательные поля и сохраните:
После создания точка появится на дашборде Alerts dashboard в списке контактных точек и станет доступна при создании алерта.
Проблемы серверов и соответствующие алерты¶
В разделе Server Stats описаны основные проблемы, которые могут возникнуть с серверами. Для каждой из них есть соответствующий алерт.
Высокая загрузка CPU¶
Проблема: Как описано в разделе Загрузка CPU, высокая загрузка процессора может привести к деградации качества обработки потоков.
Алерт: cpu_load
Срабатывает, когда средняя загрузка CPU превышает 85% за последний час.
Требуется выбор конкретного сервера.
Настройка: Заведите этот алерт для каждого сервера, чтобы вовремя узнавать о перегрузке и принимать меры по оптимизации или масштабированию инфраструктуры.
Что делать при срабатывании:
- Откройте дашборд Server Stats и посмотрите на график CPU для конкретного сервера
- Проверьте, есть ли «полка» на графике — если CPU упирается в 100% длительное время, это критично
- Обязательно проверьте график загрузки шедулера — это более достоверный индикатор проблемы
- Если нагрузка планомерно растет последние 30 дней — начинайте планировать расширение инфраструктуры
- Если это разовый всплеск — проверьте, не добавились ли новые потоки или клиенты
- Рассмотрите оптимизацию: перенос части потоков на другие серверы или масштабирование кластера
Высокая загрузка планировщика¶
Проблема: Как объясняется в мониторинге CPU, загрузка шедулера — более достоверная метрика для оценки работоспособности стримингового сервера, чем просто загрузка CPU.
Алерт: scheduler_load
Срабатывает, когда средняя загрузка системного планировщика превышает 85% за последний час.
Требуется выбор конкретного сервера.
Настройка: Обязательно настройте этот алерт для всех серверов. Высокая загрузка шедулера — более критичный показатель, чем загрузка CPU.
Что делать при срабатывании:
- Откройте график шедулера для проблемного сервера
- Если видите «полку» (планировщик упирается в предел) — это критическая ситуация, сервер не справляется
- Проверьте количество потоков и клиентов — возможно была резкая нагрузка
- Срочно перенесите часть нагрузки на другие серверы или добавьте новый сервер в кластер
- Если загрузка шедулера высокая, но CPU относительно низкий — это нормальная работа виртуальной машины, но запаса по нагрузке уже нет
Нехватка оперативной памяти¶
Проблема: В разделе Использование оперативной памяти описано, что нестабильное или чрезмерное использование RAM может привести к проблемам с производительностью.
Алерт: memory_usage
Срабатывает, когда среднее использование памяти превышает 85% за последний час.
Требуется выбор конкретного сервера.
Настройка: Настройте для всех серверов, особенно тех, которые обрабатывают большое количество потоков или выполняют транскодирование.
Что делать при срабатывании:
- Откройте график памяти для проблемного сервера
- Проверьте, стабильное ли использование памяти или оно растет
- Растущее использование памяти может указывать на утечку — обратитесь в поддержку с графиками
- Проверьте количество активных потоков — возможно их стало больше
- Убедитесь, что swap выключен (на стриминговых серверах swap не нужен и опасен)
- При необходимости добавьте RAM или перенесите часть нагрузки на другой сервер
Перегрузка диска по I/O¶
Проблема: Раздел Утилизация диска показывает, как перегрузка дисков по скорости чтения и записи может привести к ошибкам записи DVR.
Алерт: disk_io
Срабатывает, когда утилизация диска (процент загрузки по I/O) превышает 85% за последний час.
Требуется выбор конкретного сервера.
Настройка: Критически важен для серверов с DVR. Если видите collapsed writes на графиках ошибок записи, этот алерт поможет выявить проблему до появления failed writes.
Что делать при срабатывании:
- Откройте раздел Утилизация диска
- Проверьте график ошибок записи DVR — есть ли
collapsed writesилиfailed writes - Если есть
collapsed writes— хранилище начинает не успевать, это тревожная ситуация - Если есть
failed writes— это уже серьезный отказ, видео потеряно безвозвратно - Проверьте, какие диски перегружены (график процента загрузки диска)
- Для сетевых хранилищ — проверьте стабильность скорости записи, возможно проблема в сети
- Рассмотрите переход на более быстрые диски, Flussonic RAID для распределения нагрузки, или уменьшение количества DVR на этом сервере
Заполнение диска¶
Проблема: Как описано в разделе Заполнение диска, при нехватке свободного места на хранилище DVR перестаёт записывать архив.
Алерт: disk_usage
Срабатывает, когда использование дискового пространства превышает 95%.
Требуется выбор конкретного сервера.
Настройка: Настройте для всех серверов с DVR и локальным хранилищем. Порог 95% даёт запас на реакцию до полного заполнения диска.
Что делать при срабатывании:
- Откройте график заполнения диска для проблемного сервера
- Определите, какие тома или пути DVR близки к лимиту
- Проверьте политику хранения — можно ли сократить глубину архива или перенести старые записи
- Добавьте дисковое пространство или перераспределите DVR на другие серверы
- Убедитесь, что рост заполнения не связан с аномальным накоплением данных (ошибки ротации, сбой очистки)
Проблемы входящих потоков и соответствующие алерты¶
Раздел Мониторинг захвата детально описывает типичные проблемы с входящими потоками. Для их отслеживания предусмотрено несколько типов алертов.
Массовое падение потоков¶
Проблема: Как показано в примерах аварии у поставщика, может произойти одновременное падение множества потоков.
Алерт: streams_drop
Срабатывает для Watcher, когда более 10% потоков отвалились за указанный период времени.
Не требует выбора сервера – применяется ко всем серверам Watcher.
Настройка: Обязательно настройте этот алерт, если у вас Watcher. Он поможет быстро обнаружить системные проблемы у поставщика контента или в вашей сети.
Что делать при срабатывании:
- Откройте дашборд мониторинга захвата
- Посмотрите на график проблемных потоков — если много потоков упало одновременно, это системная проблема
- Как в примере аварии у поставщика — всё было хорошо и резко испортилось
- Звоните поставщику контента — возможно поломка оборудования, проблемы с дескремблированием или другая авария на их стороне
- Проверьте свою сеть — нет ли проблем с маршрутизацией или пропускной способностью
- Если абоненты не жалуются при массовом падении каналов — возможно эти каналы вам не нужны
Остановка критичных потоков¶
Проблема: Когда поток, который ранее работал, внезапно останавливается — это критическая ситуация, требующая немедленного вмешательства.
Алерт: stream_dead
Срабатывает, когда поток, который ранее имел вход, внезапно останавливается.
Можно выбрать конкретный сервер или использовать All для глобального применения.
Настройка: Используйте для мониторинга всех потоков. Если у вас есть особо критичные потоки, для них настройте отдельный алерт selected_stream_dead с более строгими параметрами уведомления.
Что делать при срабатывании:
- Откройте дашборд мониторинга захвата и выберите упавший поток
- Посмотрите на график ошибок потока — что произошло перед остановкой
- Проверьте доступность источника — возможно камера отключилась, сервер поставщика недоступен, или проблемы с сетью
- Если это RTSP камера — попробуйте переподключиться к ней вручную
- Если источник IPTV — проверьте, не истек ли срок авторизации (ошибка 403)
- Если много потоков упало одновременно — смотрите рекомендации для алерта
streams_drop
Мониторинг выбранных потоков¶
Алерт: selected_stream_dead
Аналогично stream_dead, но отслеживает только выбранные потоки.
Можно выбрать конкретный сервер или All, и необходимо выбрать, какие потоки отслеживать.
Настройка: Используйте для VIP-каналов или особо важных потоков, настроив отдельную контактную точку с уведомлением ответственных за контент.
Что делать при срабатывании:
Действия такие же, как для stream_dead, но с повышенной срочностью, так как это критичный поток. Немедленно приступайте к диагностике и восстановлению.
Нестабильные потоки (флаппинг)¶
Проблема: Как описано в разделах о вечернем пике и эпизодических провалах сети, потоки могут периодически терять и восстанавливать соединение.
Алерт: flapping_streams
Срабатывает, когда поток временно теряет вход и восстанавливается более 3 раз в течение 3 часов.
Это может указывать на проблемы с сетью, нестабильный источник входа или нестабильность на стороне сервера.
Можно выбрать конкретный сервер или использовать All для мониторинга всех потоков на предмет флаппинга.
Настройка: Настройте этот алерт для выявления системных проблем с сетью или у провайдера. Флаппинг — это предвестник полного отказа, и его нужно устранять проактивно.
Что делать при срабатывании:
- Откройте дашборд мониторинга захвата с широким временным диапазоном (12-24 часа)
- Проверьте, есть ли суточная периодичность в проблемах — как в примере вечернего пика
- Если проблемы каждый вечер с 19:00 до 01:00 — это перегрузка сети из-за пользовательского трафика
- Решение для вечернего пика: разделите сеть физически или через VLAN, настройте QoS
- Если флаппинг эпизодический без паттерна — как в примере провалов сети — проверьте загрузку свитчей
- Расширьте пропускную способность сети или оптимизируйте маршрутизацию
- Проверьте стабильность источника — возможно проблема на стороне камеры или поставщика контента
Флаппинг выбранных потоков¶
Алерт: selected_stream_flapping
Аналогично flapping_streams, но отслеживает только выбранные потоки.
Необходимо выбрать, какие потоки отслеживать, а также можно выбрать конкретный сервер или использовать All.
Флаппинг может быть вызван проблемами сети, прерываниями на стороне источника или проблемами инфраструктуры доставки.
Настройка: Используйте для критичных потоков, которые должны работать максимально стабильно.
Что делать при срабатывании:
Действия такие же, как для flapping_streams, но с фокусом на конкретный выбранный поток. Проверьте путь от источника до сервера именно для этого потока.
Рост числа оффлайн потоков¶
Проблема: Постепенное увеличение числа оффлайн потоков может указывать на нарастающую проблему в сети или у поставщика, как показано в примере эпизодических провалов.
Алерт: input_availability_raise_offline
Срабатывает, когда количество оффлайн потоков увеличивается на указанный процент, как показано на графике input_availability.
Может быть создан для всех серверов или для конкретного.
После выбора этого типа алерта появится дополнительное поле, в котором нужно указать процент увеличения оффлайн потоков, который должен вызвать срабатывание алерта.
Настройка: Установите порог в 20-30% для получения раннего предупреждения о проблемах. Это позволит среагировать до того, как проблема затронет большую часть потоков.
Что делать при срабатывании:
- Откройте дашборд мониторинга захвата
- Посмотрите на динамику роста оффлайн потоков — резкий скачок или постепенный рост
- Если рост постепенный — проблема нарастает, возможно деградация сети или источника
- Проверьте, локализована ли проблема на одном сервере или затрагивает все
- Если проблема на всех серверах одновременно — скорее всего проблема у поставщика контента
- Если только на одном сервере — проверьте сетевое подключение этого сервера
- Свяжитесь с поставщиком контента или проверьте состояние своей сети до того, как проблема затронет критичную массу потоков
Рост числа проблемных потоков¶
Проблема: Увеличение количества потоков с ошибками входа (как описано в разделе Ошибки потока) может говорить о деградации качества сети или источников.
Алерт: input_availability_raise_bad
Срабатывает, когда количество потоков с ошибками входа увеличивается на указанный процент, как показано на графике input_availability.
Может быть создан для всех серверов или для конкретного.
После выбора этого типа алерта появится дополнительное поле, в котором нужно указать процент увеличения проблемных потоков, который должен вызвать срабатывание алерта.
Настройка: Установите порог в 15-25% для раннего обнаружения деградации качества потоков. Это особенно важно для IPTV-сервисов с большим количеством каналов.
Что делать при срабатывании:
- Откройте дашборд мониторинга захвата
- Выберите самые проблемные потоки и изучите детали ошибок
- Проверьте список известных ошибок для диагностики конкретных проблем
- lost_packets — проблемы с сетью, нужно улучшать канал между источником и сервером
- ts_cc (Continuity Counter) — потеря пакетов в MPEG-TS, чинить сеть
- ts_scrambled — поток идет шифрованным, срочно разобраться с CAM модулями
- src_403/404/500 — проблемы на стороне источника, менять авторизацию или чинить источник
- Если ошибки массовые и однотипные — это системная проблема, требуется вмешательство в сеть или у поставщика
- Деградация качества приводит к рассыпанию картинки у пользователей — действуйте быстро
Ошибки входа потока (все потоки на сервере)¶
Проблема: Поток может долго работать без ошибок входа, а затем ошибки внезапно появляются — часто это первый признак деградации источника, сетевого пути или авторизации. См. раздел Ошибки потока.
Алерт: stream_input_errors_all
Срабатывает, когда на потоке появляются новые ошибки входа после периода без ошибок (чистое состояние, затем ошибки).
Требуется выбрать все сервера или конкретный. Алерт распространяется на все потоки на этих серверах — отдельно каналы перечислять не нужно.
Настройка: Используйте, когда нужен один алерт на весь headend или узел захвата, без длинного списка потоков.
Что делать при срабатывании:
- Откройте дашборд мониторинга захвата и сузьте диапазон времени вокруг уведомления
- Найдите потоки, на которых начали фиксироваться ошибки, и откройте их детали ошибок
- Сверьтесь со списком известных ошибок, чтобы понять коды (сеть, MPEG-TS, шифрование, HTTP со стороны источника и т.д.)
- Если одновременно «легло» много потоков — ищите сбой у поставщика или общую проблему на uplink
- Если затронут один или несколько потоков — в первую очередь проверьте эти источники (камера, энкодер, плейлист, учётные данные)
Ошибки входа потока (выбранные потоки)¶
Проблема: Та же ситуация, но уведомления нужны только по короткому списку важных каналов.
Алерт: stream_input_errors
Срабатывает, когда на потоке появляются новые ошибки входа после периода без ошибок.
Обязательно выберите, какие потоки отслеживать. Область действия можно задать для конкретного сервера или All — в зависимости от настроек в интерфейсе.
Настройка: Используйте для VIP или критичных для бизнеса каналов, где любая новая ошибка входа должна сразу эскалироваться; при необходимости заведите отдельную контактную точку.
Что делать при срабатывании:
Действуйте так же, как для stream_input_errors_all, но сфокусируйтесь на выбранных потоках.